

Building the Ultimate Python Package for Structural Change — With Claude Code
I needed to code a statistical test for a paper revision. Three days later, I had a working toolkit — and a roadmap to something much bigger.

I am revising a paper on forecast-error regressions with Roman Frydman. The revision requires a major extension of our empirical analysis, part of which requires the Bai-Perron test for multiple structural breaks — a standard tool in the structural change literature. The test, however, is not directly implemented in OxMetrics, the econometric software I have used for years.
OxMetrics is excellent software. Built by Jürgen Doornik and David Hendry from Oxford University — people who have done more than almost anyone to advance the econometrics of structural change — it has been my workhorse for time-series analyses. I have years of custom Ox code built on top of it. But this particular test is not available, and it illustrates a core problem with Ox: it only has a limited user base. It lacks the vast collection of open-source packages to extend core functionality that are available in alternative, free programming languages such as Python and R.
In the past, I would have spent the time required to program the Bai-Perron test myself in Ox, adding more messy and under-documented code to my existing workflow. Code for my eyes only, not to be shared. Safe. Familiar.
This time, however, I chose a new path. Three days later, I had the first version of a working Python package for dealing with structural change in time-series models on GitHub — one that I would not have dreamed of building only weeks before I started. My head is still exploding.
This post is about how that happened.
The Inspiration
Two people deserve credit for what came next. Scott Cunningham has been writing about using Claude Code for econometric analysis (for example, here, here, and here) — showing, in real time, what becomes possible when an economist works with an AI coding tool that understands the domain. Isaac Gerber has been writing about using Claude Code to create the ultimate Python package for difference-in-difference estimation and testing (for example, here, here, and here). Their posts caught my attention at exactly the right moment.
I have integrated AI into several parts of my daily workflow over recent months. So my initial thought was to use AI to create my own Ox code for the Bai-Perron test. That should be fairly easy, and AI would surely help me do it faster and better than I could do on my own.
But what struck me in Cunningham’s and Gerber’s examples was not that AI could write econometric code — we have known that for some time. It was that Claude Code is not a chatbot. It is a local agent: once installed, it reads your codebase and understands the context. It plans in collaboration with you — asking questions, making suggestions, proposing approaches. And then it executes directly in your project: creating files, running tests, catching errors, and iterating until things work. It does not generate code for you to copy and paste. It builds things. Cunningham was performing entire empirical analyses this way. Gerber was creating a professional Python package from scratch.
I realized I could do both: use Claude Code to build the ultimate Python package for structural change and use it to perform the empirical analysis for our paper revision. I assumed AI would help me write code faster. I didn’t expect it to change what felt feasible to build.
More Than a Test
I have spent years working on the econometrics of structural change — developing theory, doing empirical analyses, writing papers about what happens when the economy undergoes shifts that cannot be captured by a fixed model. The central argument of this Substack is that the economy undergoes nonrepetitive structural changes, and that our models and methods need to take this seriously.
Yet, the econometric software to do this well is still surprisingly scarce: even the best tools do not make structural change the organizing principle. OxMetrics enables you to identify level-shifts using the Autometrics algorithm with step-indicator saturation, but additional manual coding is required to use this approach to identify other types of structural breaks or to implement the Bai-Perron test. Python has excellent individual packages — statsmodels for regression, arch for volatility models, various implementations of individual tests. The R package strucchange implements several tests for structural breaks.
But there is nothing that integrates the entire workflow around structural change: detecting breaks, estimating models regime by regime, monitoring parameter stability over time, and visualizing all of it in a way that makes structural instability visible.
This is the gap. Not a missing test, but a missing toolkit for a workflow that takes structural change as the starting point of the empirical analysis. In a previous post, I outlined five principles for forecasting in a changing economy — monitor for breakdowns, evaluate locally, hedge model risk, and so on. Those principles need tools to make them operational. Equivalently, our research on developing economic theory that takes structural change seriously needs the econometric tools that enable identifying such breaks robustly from the time-series data, estimating the relationships of interest during periods where they appear stable, and testing whether those relationships hold out of sample.
So the ambition became: use Claude Code to build the ultimate Python package for time-series econometrics and forecasting that treats structural change as the central concern. Not as an afterthought or a special case, but as the default assumption. A package where the first question is always: has the relationship changed?
I called it regimes.
How I Actually Built This
Let me explain what I actually did, because the “I built X with AI” genre can sometimes make things sound easier than they are.
Building regimes with Claude Code involved three distinct phases, and none of them was “type a prompt and get a package.”
Phase 1: Context
Before a single line of code was written, I spent considerable time teaching Claude about my research. Claude Code reads a file called CLAUDE.md from your project root — a persistent document, not a one-off prompt. Think of it as the memo you would write for a new research assistant’s first day: here is what we work on, here is why it matters, here are the tools we use, here are the questions we are trying to answer. Any economist could write one for their own research — or even better: interact with Claude Code to get it to write it for you, which is what I did.
In practice, you do this by opening Claude Code in your workspace folder. Mine is conveniently a folder called \workspace and I primarily work in VS Code. After downloading and installing Claude Code on my laptop, I open my \workspace folder in VS Code, open the terminal, type claude, and hit enter. This starts Claude Code from the root folder ~\workspace\.
The first thing I did was to enter Claude Code’s Planning Mode and start writing about myself, my work, and my research. After writing a few lines, I end by telling Claude Code to follow up with additional questions that it needs me to answer. It does exactly that, and I answer the questions.
I also feed Claude Code my research papers — for example, I upload the papers I currently work on to the subfolder ~\workspace\research\working-papers\, enter Planning Mode, and tell Claude Code in plain English that I have added the papers to this folder — provide links to my writings on LinkedIn, etc.
At the end, Claude Code distills all the information and saves it in the ~\workspace\CLAUDE.md file. Here is what part of mine currently looks like:
# Research Assistant Context
## Mission
Develop economic theory and practical forecasting tools for a changing world, taking structural change seriously.
## Role
**Founder and Director**, INET Center on Knightian Uncertainty (https://knightianuncertainty.org/)
## Research Focus
- **Core idea**: The economy undergoes nonrepetitive structural changes. Since future regimes are unobserved, perfect probabilistic knowledge is impossible — we face Knightian uncertainty, not just risk.
- **Collaboration**: Roman Frydman (New York University)
- **Framework**: Opening macroeconomic and finance models to unforeseeable change; rational expectations under Knightian uncertainty
## Key Research Questions
1. How can we formalize unforeseeable change, Knightian uncertainty, and rational expectations?
2. What are the implications for understanding markets?
3. What are the policy implications?
4. How can we design forecasting workflows that acknowledge unforeseeable change?And the technical setup — the methods I use and the libraries I work with:
**Econometric Methods**: Autoregressive (AR) models, Vector Autoregressions (VARs), Autoregressive Distributed Lag (ADL) models, linear regressions for time-series data (including forecast-error regressions)
**Python Stack**: `pandas` for data handling, `numpy` for numerical operations, `statsmodels` for econometrics (AR, VAR, ARDL, OLS with HAC standard errors), `matplotlib` for visualization, `scipy` for optimization and statistical testsThis is not prompt-and-pray. It is building a shared understanding — the kind of understanding that a good research assistant would need before being useful. The investment is a day of writing in plain English. The return is that every interaction starts from shared understanding rather than from scratch.
Phase 2: Planning
With context established, we moved to collaborative architectural planning. Again, entering Planning Mode, we discussed what the package should do, how to organize it, what conventions to follow, and what to build first versus defer. This produced two artifacts: a technical specification and a phased roadmap.
Two design decisions shaped everything that followed.
The first was to build on the existing Python ecosystem rather than writing estimation routines from scratch. The package extends statsmodels and pandas — delegating OLS and AR estimation to statsmodels, using pandas for time-series indexing — so that the new code focuses on what is genuinely missing: the structural change layer on top. This is not just a time-saver. It means the package inherits decades of tested, peer-reviewed numerical code, and users can move between regimes and the broader Python ecosystem without friction.
The second was to separate estimation from detection. Models (OLS, AR, ADL) live in one class hierarchy; break tests (Bai-Perron, and eventually Chow, CUSUM, and others) live in another. Then bridge them: every model has a .bai_perron() method that hands itself to the test, and test results have a .to_ols() method that converts detected breaks back into a fitted model. This keeps each component clean — you can use models without tests, or tests without models — while enabling a smooth workflow when you need both. For economists: think of this as the organizational chart of the codebase, with a clear bridge between the two divisions:
Models (estimation):
RegimesModelBase
├── OLS
├── AR
└── ADL
↕ .bai_perron() / .to_ols()
Break Tests (detection):
BreakTestBase
└── BaiPerronTestWe also mapped out a version roadmap — seven planned phases stretching from foundation through a complete forecasting workflow:
| Version | Description |
|---------|-------------|
| 0.1.0 | Foundation: OLS, AR, Bai-Perron test, visualization |
| 0.2.0 | Rolling/recursive estimation, ADL model, diagnostic plots |
| 0.3.0 | Structural break tests (Chow, CUSUM, Andrews-Ploberger), Markov-switching |
| 0.4.0 | Autometrics model selection, indicator saturation |
| 0.5.0 | Documentation, examples, PyPI release |
| 0.6.0 | VAR, cointegration, panel data, bootstrap |
| 0.7.0+ | End-to-end forecasting workflow with structural change |Each phase was broken down into granular tasks and continuously revised as we worked on building the package. Here is a sample from the Phase 2 checklist, to give a sense of the level of detail:
- [x] RollingOLS / RecursiveOLS classes
- [x] Model integration (`.rolling()`, `.recursive()` methods)
- [x] Enhanced Bai-Perron: confidence intervals for break dates, sequential testing, information criteria (BIC/LWZ)
- [x] ADL class with flexible lag specification
- [x] Lag selection via AIC/BIC grid search
- [x] PcGive-style diagnostic plots
- [x] Target: 80%+ test coverage (achieved: 88% with 540 tests)Notice that the roadmap is guided by my research needs. For the paper revisions, I needed the Bai-Perron test in simple linear regression and autoregressive models, so we built those first. Then rolling and recursive estimation — central to any workflow that monitors for structural change, although I am actually not a big fan as they are difficult to interpret. Then ADL models — a standard specification in macroeconometrics. This is briefing an architect, not asking a contractor to improvise.
Phase 3: Iteration
This is where most of the time went. The basic cycle: Claude Code builds a component — say, the Bai-Perron test implementation. It generates examples as interactive Jupyter notebooks. I run the code line-by-line. I examine the output and compare it to known results: established implementations and my own OxMetrics output. When something does not match, I investigate. Sometimes the issue is a bug. Sometimes it is a difference in convention. I instruct Claude on what to change, it makes the changes, and we go again. Often many cycles until convergence.
The progression was rapid. Two days for the foundation — version 0.1.0 with basic models and the Bai-Perron test. Then systematic improvement into version 0.2.0 with rolling estimation, ADL models, diagnostic plots, and comprehensive testing. By the end:
Test coverage increased from 17.88% to 88% (540 tests total)
“Tests” here means automated software checks — small programs that run a piece of code and verify it produces the expected output. Not 540 statistical hypothesis tests, but 540 automated checks that the code works correctly across a range of scenarios. I will return to why this matters below. But first, let me give a concrete example of what the verification process looks like. When I compared the Bai-Perron test output from regimes against results from established programs, several discrepancies surfaced. Some turned out to be genuine bugs. Others turned out to be differences in convention — how break dates are indexed (does break k refer to the last observation of the old regime or the first observation of the new one?), how the trimming parameter is set, how confidence intervals are computed. Working through these required understanding the econometric theory well enough to distinguish a bug from a convention choice.
But iteration did not just fix bugs — it also improved the design. Working through example notebooks, I found myself repeatedly fitting a model, then wanting to test it for breaks, then re-fitting with the detected breaks applied. That recurring workflow need is what drove the creation of the .bai_perron() and .to_ols() bridge methods introduced earlier — the connection between the two class hierarchies. The architecture diagram in Phase 2 did not come from a whiteboard session. It emerged from repeatedly using the package and noticing what was awkward.
The critical point: domain expertise is not optional. I need to know what correct output looks like. I need to understand the econometric theory well enough to spot when something is off. I need to know which edge cases matter — what happens at the boundaries of the sample, how the test behaves with small segments, whether the asymptotic distribution is right. Claude Code is remarkably capable, but it is the economist who must verify and direct.
The result is not something either of us could have produced alone. I could not have written this package without AI — not in this timeframe, not with this level of testing and documentation. But Claude Code could not have built it without an economist who knows what structural change means, what Bai-Perron should produce, and what a useful empirical workflow looks like.
What Exists Now
After continued iteration, `regimes` is now at version 0.2.0, and it can do considerably more than that initial foundation:
Linear regression, autoregressive, and autoregressive distributed lag models — all with structural breaks specified at known break dates
The Bai-Perron test for detecting multiple structural breaks endogenously — the test that started this whole project
Rolling and recursive estimation — fit models on expanding or moving windows to monitor how parameters evolve over time
Regime-specific estimation — split the sample at break dates and fit separate models to each regime
Diagnostic visualization — plots that make structural instability visible: coefficient paths, break dates, regime-specific fits
Here is an example output based on simulated time-series data with a structural break at t=100.
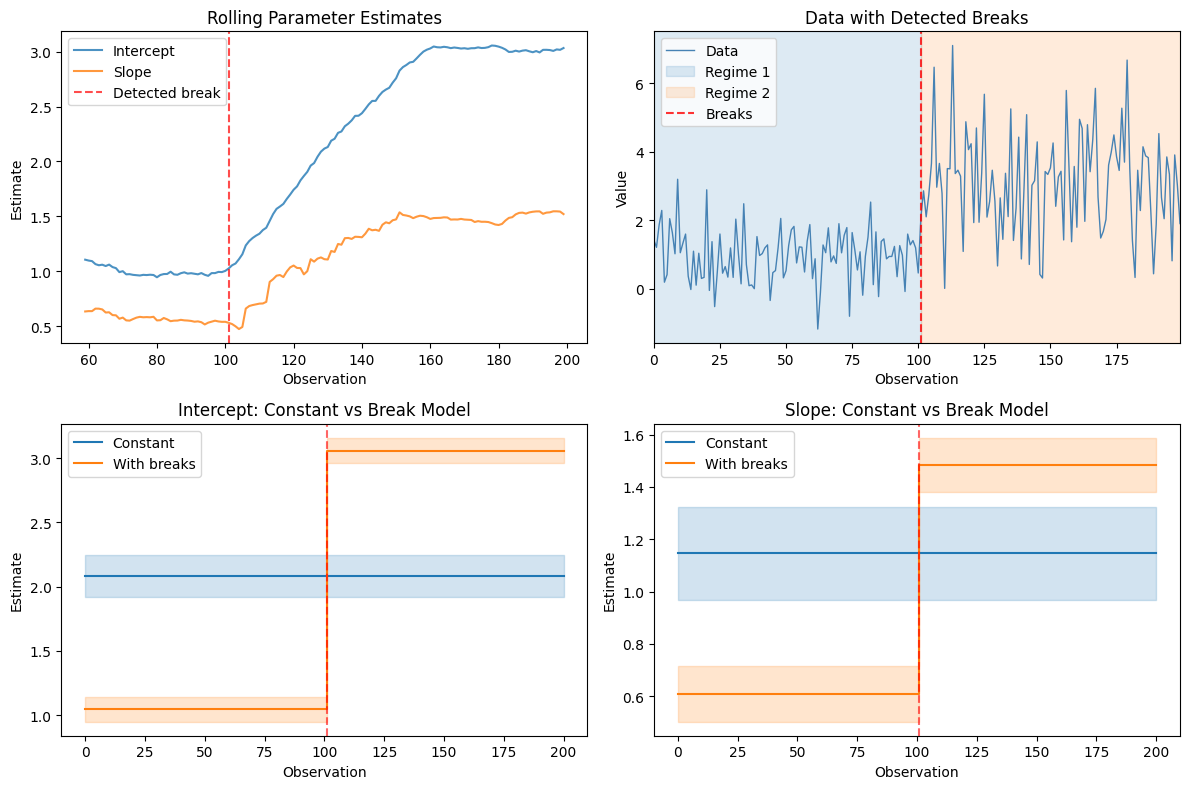
Results have been verified against OxMetrics and established implementations, with verification of some edge cases still in progress. The verification process — economist checks AI-generated code output against known results — is not a nice-to-have. It is the foundation of the whole approach.
The package is available on GitHub. It is open source and free to use. I will continue adding features and check the robustness. I welcome feedback from anyone working on similar problems.
A Prediction About Empirical Work
Let me step back from the personal narrative and make a broader claim.
Right now, many economists are skeptical about using AI to write code for empirical analysis. I understand the skepticism. If you cannot see every line the AI wrote and verify its logic, how can you trust the results?
I think this skepticism will flip. Within a year or two, we will be skeptical in the opposite direction: skeptical of empirical code that has not been created with AI assistance and, at a minimum, extensively tested and checked by AI.
Here is why. Consider the 88% test coverage in regimes — 540 tests that systematically verify the package’s behavior across a wide range of scenarios and edge cases. I would not have achieved that level of coverage working alone. It is not because I do not value testing. It is because the marginal cost of writing tests drops dramatically with AI assistance, and when costs drop, the equilibrium quantity rises. AI makes it feasible to do the careful, comprehensive testing that we always knew we should do but rarely had time for.
The same logic applies to documentation, to code review, to systematic checking of edge cases, to producing credible replication packages for empirical analyses. AI does not lower the standard for empirical work. It raises the floor — making it practical to meet standards that were previously too costly to achieve routinely. It is a tool that enables us to do things we previously didn’t have time to do or couldn’t do.
This is not about AI replacing economists. The domain expertise is more important than ever. But the economist’s role shifts: less time typing code, more time thinking about what the code should do and whether the results make sense. Less writing code, more architectural direction. That is a better allocation of comparative advantage.
What Comes Next
The current version handles estimation and break detection. The next steps will extend the package in two directions.
First, a broader toolkit for identifying structural change: formal break tests beyond Bai-Perron, Markov-switching models, and autometrics-style indicator saturation — the automated approach to finding breaks pioneered by Hendry, Doornik, and Castle at Oxford. The goal is to be able to throw multiple detection methods at a time series model and show whether they agree through publication-ready tables and visualizations.
Second, and more importantly: forecasting. The longer-term ambition is to turn regimes into an end-to-end toolkit for a forecasting workflow that takes structural change seriously — from data to model selection to break detection to forecast to forecast evaluation. That is the part that does not exist anywhere, and it is the part that matters most.
A few weeks ago, I would not have considered building any of this. The skills required — not just the econometric theory, which I have, but the software engineering, the testing frameworks, the package architecture — would have taken months to develop to the point where the project made sense. Claude Code changed that calculation. Not by replacing the economist, but by filling in the skills that the economist lacks, guided by the knowledge that the economist has.
The package is on GitHub.
Try it. Break it. Tell me what it should do that it does not. I will keep you posted on the development as it progresses.
P.S. In case you are wondering: yes, I also used AI to write this post. Same principle as the code — it starts and ends with my ideas, but the process in between is faster and sharper than working alone.